
There are several new AI and NLP technologies that you can use for personal knowledge management. I’ll go over a few useful AI techniques and how they differ from what we’ve seen before.
The “Next Generation” “semantic search” technologies are more intelligent than we’ve seen before because they understand the meaning behind the text and not just the specific keywords they have in common.
For example, I could search for “food” and find an article on “Burritos” even if the specific word “food” doesn’t appear in the “Burritos” article. Semantic Search enables a much more robust search because you don’t need to guess particular words to find the article you want, and you can search by meaning and intent.
These new technologies allow you to search, summarize and categorize your notes. You can also use AI to generate new notes instead of just analyzing them.
Here are a few of my favorite new techniques and technologies. Some of these you can use today, but many haven’t been built into any notes app. The big tech companies are using all these techniques, but the average user doesn’t know they exist.
Graph Analysis
Graph Analysis or graph theory studies graphs, which are relationships between objects. The main ideas are that “nodes” have connections to other nodes, and “edges” are the connections between nodes. You can imagine a social network with people and their friends.
Graph Theory is handy for analyzing social networks. Graph theory can determine who the most influential members of a group are.
Graph Theory can also be used to find relationships between your notes.
This type of analysis works well for bidirectional note-taking apps with backlinks because the links provide a lot of information about the relationship between the notes. AI can then discover “hidden” relationships between notes.
Game of Thrones Social Network
Here’s what Game of Thrones would look like if it were a social network. You can see how all the characters such as “Jon Snow” and “Daenerys Targaryen” are connected.

Adamic Adar and “Link Prediction”
The Adamic–Adar index is a method to “predict” links in a social network according to the number of shared links between two nodes.
Adamic-Adar is also a measure of how “similar” two notes in a graph are, even if you don’t link the notes directly.
This technique can suggest new friends or pages on a social network based on your friends and interests.
The technique could also suggest new links between notes, depending on the shared connections between them and their neighbors.
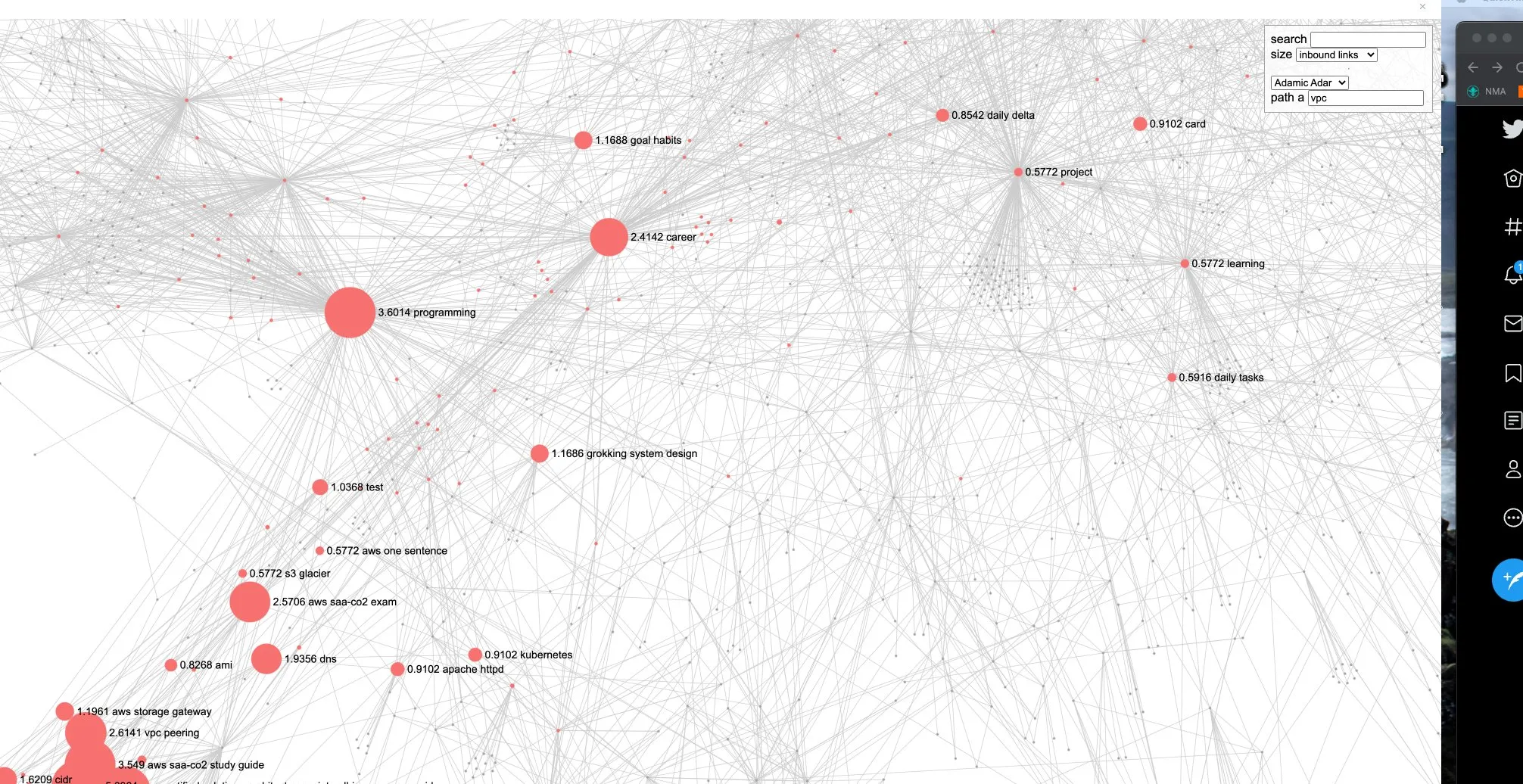
This Adamic-Adar link prediction algorithm is implemented in the Logseq graph analysis plugin.
It shows how similar notes are, even if they aren’t linked directly
These are notes closely related to “AWS VPC”.
The size of the bubble shows the strength of the relationship.

It can find hidden relationships throughout your entire graph, even from very distant links
These are more distant notes related to “AWS VPC”.
They don’t have any close links, but we can still detect that these ideas are related.
Adamic-Adar index is similar to a calculation called the Jaccard index, which is an older method of computing similarity.
Shortest Path
There are also algorithms for finding the shortest paths between your notes.
The logseq graph analysis plugin has a good tool for exploring paths between notes.

@trashhalo’s logseq graph analysis plugin
Co-Citations
Co-citation is the frequency with which two documents are cited together by other documents.
If at least one other document cites two documents in common, these documents are said to be co-cited.
The more co-citations two documents receive, the higher their co-citation strength and the more likely they are semantically related.

Community Detection

Community Detection Algorithms
Community detection can be used in machine learning to detect groups with similar properties and extract groups.
A community is a set of nodes that are densely connected
Community detection is similar to clustering. Clustering is a general machine learning technique in which similar data points are grouped into the same cluster based on their attributes.
Community detection is specifically tailored for network analysis and depends on a single attribute type called edges. The clustering you’ve seen before was likely simpler and based on direct attributes.
See this guide to Community Detection Algorithms for more
Label Propagation

Original image by Gordon Johnson from Pixabay.
Given a “label” like “liking cricket,” can we predict how likely someone is to like cricket based on their friends?
See “Label Propagation Demystified” (Towards Data Science, no longer available) for more.
Summarization

Summarization is summarizing information in large texts for quicker consumption.
It is my favorite area of research, and I’ve found it endlessly helpful in consuming more information and learning more effectively. It’s easier to remember what you read if you have a summary of the source material in your notes.
There are two types of machine summarization: Extractive (the old way, based on keywords) and Abstractive (the new way, based on meaning).
The older extractive methods are fast and free, but the new abstractive methods produce beautiful summaries that are original explanations instead of just key sentences pulled from the article.
Extractive Summarization
Extractive summarization is the traditional method that pulls out the most significant sentences in a document.
The summary from Extractive Summarization is written using almost the same sentences from the original text.
TextRank
TextRank is an extractive summarization technique.
TextRank is based on the idea that words which occur more frequently are significant. Therefore, sentences containing highly frequent words are important.
It is similar to Google’s PageRank algorithm, which decides the websites to show you in search based on how many other pages link to that website.
Other methods are based on this same idea, including “Inverse Document Frequency,” which ranks the importance of words based on how “rare” they are in other documents.
Abstractive Summarization
Abstract summarization is a state-of-the-art method that rephrases the text and generates new original phrases.
Some examples of AI “models” or programs that can do this are Open AI’s GPT-3, Facebooks BERT, and Google’s T5.
These can turn long articles into excellent summaries that explain the essential concepts in a few words, even using terms that don’t appear in the original article in its explanation.
These new tools show an “understanding” of the text, how it relates to other topics, and how to create a custom-tailored explanation of the text.
Out of all these, the best by far is OpenAI’s GPT-3, but it is expensive.
Semantic Search and Vector Embeddings
Semantic Search
“Semantic Search” is a way of searching documents by meaning instead of just keywords.
For example, you could search for pages on food, and a page on burritos would appear, even if the burrito page never mentions the specific word “food.”
Most techniques around semantic search involve breaking down the text into “vector embeddings,” which are representations that can be searched in systems like “vector databases.”
Vector Embeddings
Vector embeddings are central to many NLP, recommendation, and search algorithms.
Vector embeddings are just lists of numbers that have special meaning relative to other vectors.

Google invented a tool called “Word2Vec” which converts text into n-dimensional vector coordinates. You can plot these words in visual space 3D to see words with similar “meaning” nearby
For example, words like “king” and “queen” and “prince” will all cluster together. Same with synonyms (“walked,” “strolled,” “jogged”).

We can use tools to explore the similarity of these words in 3D space.
Exploring Similar Words in 3D Space
Words most similar to “football” in meaning


Words Similar to “guitar”
All Words
Handwritten numbers
Handwritten numbers are shown in terms of visual similarity to each-other
You can see that “7” is similar to “9”, so these numbers are grouped closely together in 3D space.
GPT-3 and Large Language Models
GPT-3 is a model made by OpenAI, based on a “transformer architecture.” GPT-3 was trained in an unsupervised manner on a large amount of text gathered online.
GPT-3 works by predicting the next word given a sequence of words.
It can do many tasks it hasn’t been trained to do.
The most powerful thing about GPT-3, is that given a few examples of a new task, it can quickly learn how to do it.
For example, you can ask:
“I love you → Te quiero. I have a lot of work → Tengo mucho trabajo. GPT-3 is the best AI system ever → _.”
And it will know to translate the sentence into Spanish.
According to studies, it can generate “news articles” on a given topic that humans can barely distinguish as being written by AI.
It can do many different things, given a “prompt,” just an English language description of what you want to do.
Most AI until now has focused on analysis, but I’m excited by the generative capabilities of new AI like GPT-3.
Using the OpenAI Fine Tuning API,we can build very powerful “prompts”
OpenAI Embeddings
OpenAI also has a system to process text and images into “vector embeddings” that can be used in NLP and machine learning algorithms. One exciting thing about OpenAI is its method processes text and images into the same 3d space. That means that you can see how similar conceptually words are to images and vice versa.
Traditional NLP
You can still accomplish much with older techniques that look more at words than conceptually.
These methods are cheaper and faster, so they should be used whenever possible.
Sentiment Analysis
Sentiment analysis detects the emotion of the text and grades it as positive or negative.
For example, just by reading your movie review, a machine can tell if you liked it or not.

Entity Recognition
You can use NLP to extract “important” things from plain text, such as person names, organizations, locations, time, etc.
This could pull certain critical pieces of information out of your notes like peoples, places, emails, etc.

Text Classification
Text can be organized into groups, either by simple rules or statistics.
One example of simple machine-based classification is a “bag of words” representation, the number of times each word occurs in the text.
You could imagine using this to suggest backlinks in your notes or finding similar notes.
Keyword Extraction
Keyword extraction algorithms like TextRank allow you to find the essential words in a text and how they’re related.
These are also good ideas for backlinks or similar pages.

Source: TextRank for Keyword Extraction by Python (Towards Data Science, no longer available)
Conclusion
I hope you enjoyed this overview of NLP and AI techniques relevant to note-taking.
Most big tech companies already heavily use these ideas, but I hope individuals find ways to adapt the latest AI techniques to their needs.